Chapter 15 End-to-end testing
In the last chapter, we built a backtesting system that replays historical trade events through our trading strategy. We ran 200K+ events through the system and watched it generate hundreds of orders. But we verified everything manually - checking database tables, reading logs, eyeballing results.
Here’s the problem with that approach: it doesn’t scale. Every time we refactor, we’d need to repeat the same manual verification. And manual verification has a nasty habit of becoming “skip verification” when deadlines loom.
What we need is automated end-to-end testing. We’ll broadcast carefully crafted trade events and assert that the right orders appear in the database. The test will prove our trading flow works - from receiving an event to placing orders.
Along the way, we’ll pay off some technical debt.
Remember when we put PubSub and TradeEvent in the streamer app?
That shortcut is about to cause a dependency cycle, and we’ll fix it properly by introducing a core application.
15.1 Objectives
- decide on the tested functionality
- implement basic test
- introduce environment based config files
- add convenience aliases
- cache initial seed data inside a file
- update seeding scripts to use the BinanceMock
- introduce the core application
15.2 Decide on the tested functionality
We’ve reached the stage where we have a working trading system - but “it works on my machine” isn’t good enough. To ensure it keeps working after refactoring, we need automated tests. We’ll start with an end-to-end test that confirms the whole trading flow works: events come in, orders go out, data lands in the database.
To perform tests at this level, we will need to orchestrate databases together with processes and broadcast trade events from within the test to cause our trading strategy to place orders. We will be able to confirm the right behavior by checking the database after running the test.
These tests should be rare in your test suite - they’re brittle and require substantial effort to set up and maintain. My rule of thumb: reserve end-to-end tests for major “happy paths” only.
Let’s look at the current flow of data through our system:
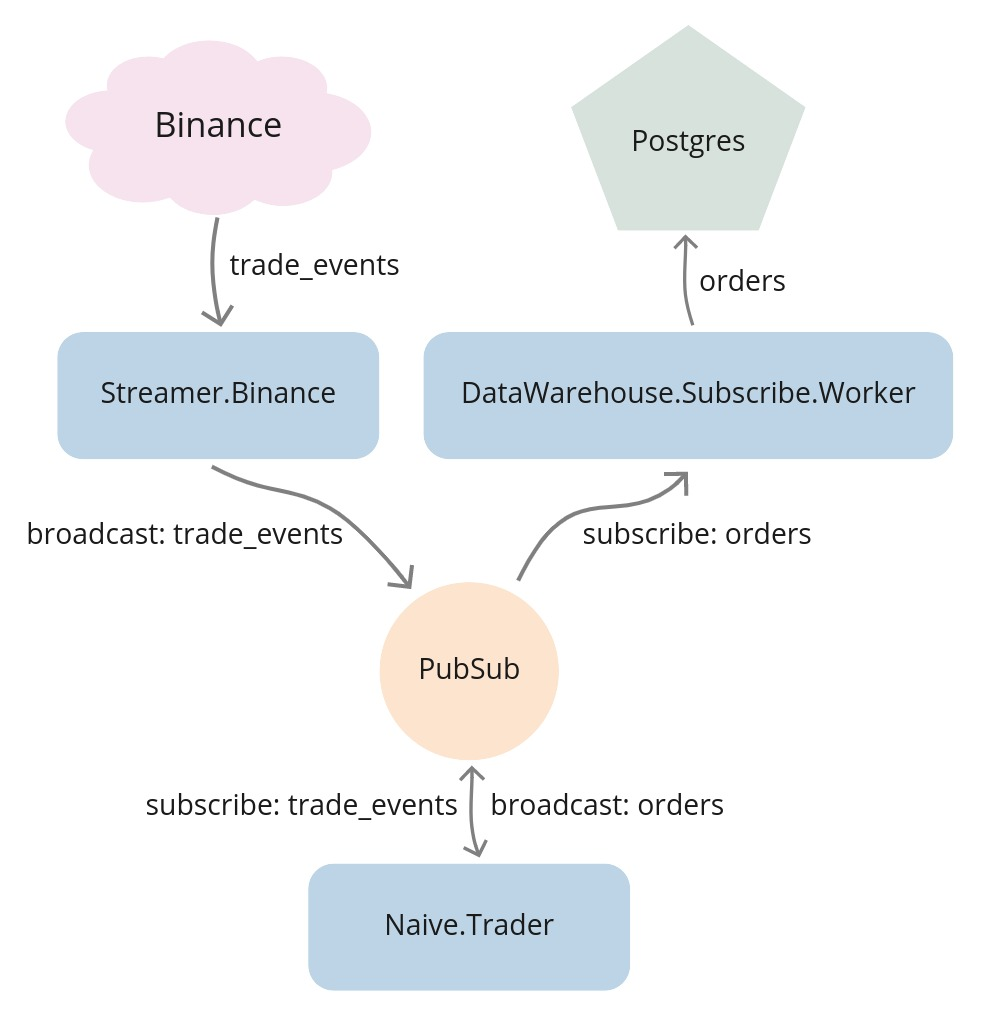
Currently, the Streamer.Binance establishes a WebSocket connection with Binance.
It decodes the incoming trade events and broadcasts them to PubSub(TRADE_EVENTS:#{symbol} topics).
PubSub then sends them to the Naive.Trader processes. As those processes place orders(or orders get filled),
they broadcast orders to the PubSub(ORDERS:#{symbol} topics). The DataWarehouse.Subscriber.Worker processes subscribe
to the broadcasted orders and store them in the database.
What we could do is to stop all the Streamer.Binance processes and broadcast trade events directly from the test.
We would then be able to fine-tune the prices inside those events to run through the full trade cycle:
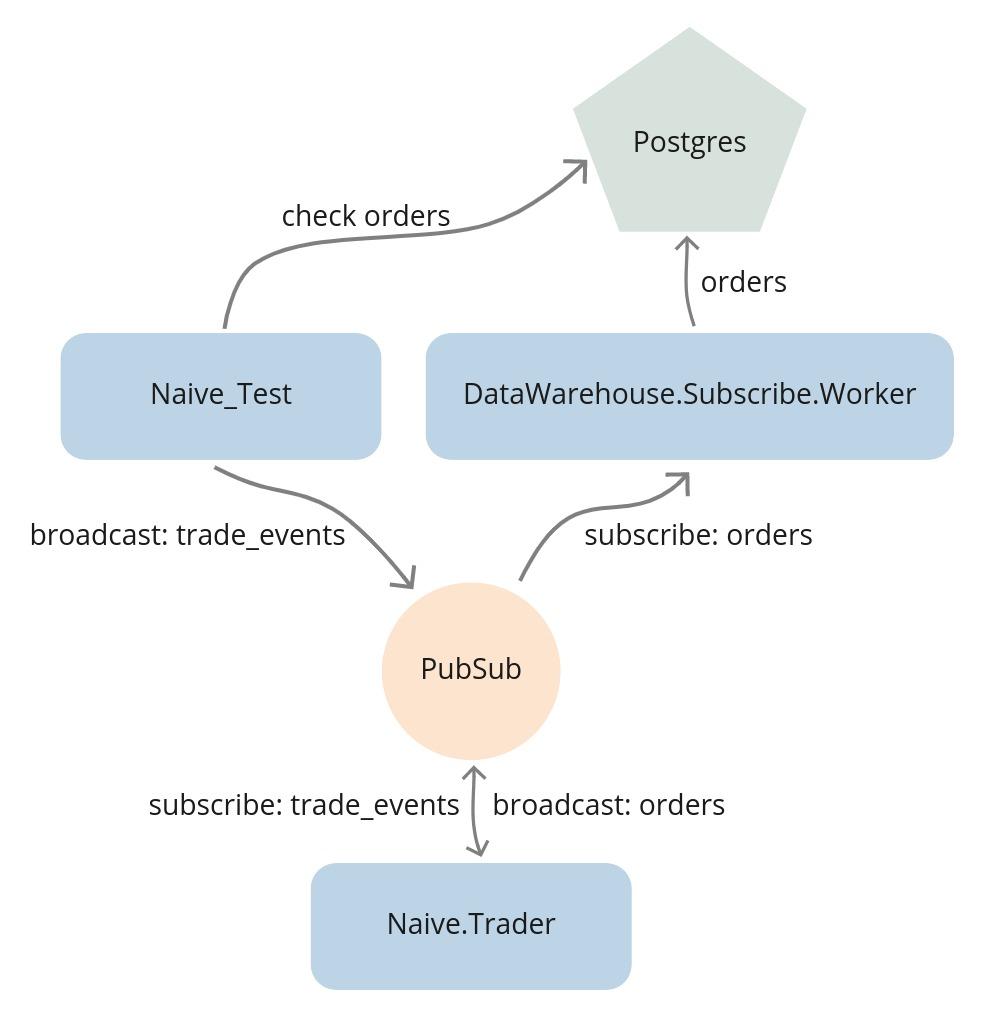
This would allow us to fetch orders from the database to confirm that trading indeed happened.
15.3 Implement basic test
We will place our test inside the NaiveTest module inside the apps/naive/test/naive_test.exs file.
First, we will need to alias multiple modules that we will use to either initialize or confirm the results:
# /apps/naive/test/naive_test.exs
...
alias DataWarehouse.Schema.Order
alias Naive.Schema.Settings, as: TradingSettings
alias Streamer.Binance.TradeEvent
import Ecto.Query, only: [from: 2]Now we can update the generated test to have a tag in front of it:
We will use this tag to select only this test when we are running the integration tests.
The first step will be to update the trading settings to values that will cause trading activity:
# /apps/naive/test/naive_test.exs
...
test "Naive trader full trade(buy + sell) test" do
symbol = "XRPUSDT"
# Step 1 - Update trading settings
settings = [
profit_target: 0.001,
buy_down_interval: 0.0025,
chunks: 5,
budget: 100.0
]
{:ok, _} =
TradingSettings
|> Naive.Repo.get_by!(symbol: symbol)
|> Ecto.Changeset.change(settings)
|> Naive.Repo.update()As we updated the trading settings, we can now start trading:
# /apps/naive/test/naive_test.exs
# `test` function continued
...
# Step 2 - Start trading on symbol
Naive.start_trading(symbol)Before we start broadcasting events, we need to ensure that the DataWarehouse application will store resulting orders into the database:
# /apps/naive/test/naive_test.exs
# `test` function continued
...
# Step 3 - Start storing orders
DataWarehouse.start_storing("ORDERS", symbol)
:timer.sleep(5000)Additionally, as seen in the above code, we need to allow some time(5 seconds above) to initialize trading and data storing processes.
We can now move on to broadcasting trade events:
# /apps/naive/test/naive_test.exs
# `test` function continued
...
# Step 4 - Broadcast 8 events
[
# below event will trigger
# buy order placed @ 0.4307
generate_event(1, 0.43183010, "213.10000000"),
# above the buy price - ignored
generate_event(2, 0.43183020, "56.10000000"),
# above the buy price - ignored
generate_event(3, 0.43183030, "12.10000000"),
# event at the expected buy price
# it should trigger fetching the buy order
# and placing a sell order @ 0.4319
generate_event(4, 0.4307, "38.92000000"),
# event below the expected buy price
generate_event(5, 0.43065, "126.53000000"),
# event at exact the expected sell price
# it should trigger fetching the sell order
# and trader process to exit
generate_event(6, 0.4319, "62.92640000"),
# below event will trigger
# buy order placed @ 0.4309
generate_event(7, 0.43205, "345.14235000"),
# above the buy price - ignored
generate_event(8, 0.43210, "3201.86480000")
]
|> Enum.each(fn event ->
Phoenix.PubSub.broadcast(
Streamer.PubSub,
"TRADE_EVENTS:#{symbol}",
event
)
:timer.sleep(10)
end)
:timer.sleep(2000)The above code will broadcast trade events to the PubSub topic that the trader processes are subscribed to. It should cause 3 orders to be placed at specific prices.
A Note on Testing Timing: We are using :timer.sleep/1 here to allow the asynchronous processes
time to finish their work. In a professional CI/CD environment, this is discouraged because it leads
to slow and brittle tests (flakiness). A robust solution would involve the test process subscribing
to the PubSub topic to receive a ‘work finished’ message or using a polling assertion library to wait until the database record exists.
In the last step, we will confirm this by querying the database:
# /apps/naive/test/naive_test.exs
# `test` function continued
...
# Step 5 - Check orders table
query =
from(o in Order,
select: [o.price, o.side, o.status],
order_by: o.inserted_at,
where: o.symbol == ^symbol
)
[buy_1, sell_1, buy_2] = DataWarehouse.Repo.all(query)
assert buy_1 == [Decimal.new("0.4307"), "BUY", "FILLED"]
assert sell_1 == [Decimal.new("0.4319"), "SELL", "FILLED"]
assert buy_2 == [Decimal.new("0.4309"), "BUY", "NEW"]That finishes the test function. The final addition inside the NaiveTest module will be to add a private helper function
that generates trade event for the passed values:
# /apps/naive/test/naive_test.exs
...
defp generate_event(id, price, quantity) do
%TradeEvent{
event_type: "trade",
event_time: 1_000 + id * 10,
symbol: "XRPUSDT",
trade_id: 2_000 + id * 10,
price: price,
quantity: quantity,
trade_time: 5_000 + id * 10,
buyer_market_maker: false
}
endThis finishes the implementation of the test, but as we are now using DataWarehouse’s modules inside the Naive application,
we need to add data_warehouse to the dependencies:
We could now run our new integration test, but it would be run against our current(development) databases. In addition, as we will need to reset all the data inside them before every test run, it could mean losing data. To avoid all of those problems, we will use separate databases for testing.
15.4 Introduce environment based config files
Currently, our new test is running in the test environment (the MIX_ENV environmental variable is set to "test"
whenever we run mix test), but we do not leverage that fact to configure our application for example: to use test databases as mentioned above.
Configuration for our applications lives in config/config.exs configuration file. Inside it,
we have access to the name of the environment, which we will utilize to place an environment based import_config/1 function:
Now we will create multiple config files, one for each environment:
/config/dev.exsfor development:
/config/test.exsfor future “unit” testing:
/config/integration.exsfor end-to-end testing:
# /config/integration.exs
import Config
config :streamer, Streamer.Repo, database: "streamer_test"
config :naive, Naive.Repo, database: "naive_test"
config :data_warehouse, DataWarehouse.Repo, database: "data_warehouse_test"/config/prod.exsfor production:
After adding the above environment-based configuration files, our test will use the test databases.
There’s one more remaining problem - we need to set those test databases before each test run, and as this process requires multiple steps, it’s a little bit cumbersome.
15.5 Add convenience aliases
To be able to run our new integration test as easily as possible without bothering ourselves with all the database setup,
we will introduce aliases in both the streamer and naive applications that will wrap seeding the databases:
# /apps/naive/mix.exs & /apps/streamer/mix.exs
def project do
[
...
aliases: aliases()
]
end
defp aliases do
[
seed: ["run priv/seed_settings.exs"]
]
endInside the main mix.exs file of our umbrella, we will use those with usual ecto’s commands like ecto.create and ecto.migrate:
# /mix.exs
def project do
[
...
aliases: aliases()
]
end
defp aliases do
[
setup: [
"ecto.drop",
"ecto.create",
"ecto.migrate",
"do --app naive --app streamer cmd mix seed"
],
"test.integration": [
"setup",
"test --only integration"
]
]
endWe can now safely run our test:
Wait… Why do we need to set the MIX_ENV before calling our alias?
So, as I mentioned earlier, the mix test command automatically assigns the "test" environment when called.
However, our alias contains other commands like mix ecto.create, which without specifying the environment explicitly,
would be run using the dev database. So we would set up the dev databases(drop, create, migrate & seed) and then run tests on the test databases.
So our test is now passing, but it relies on the database being setup upfront, which requires seeding using a couple of requests to the Binance API.
15.6 Cache initial seed data inside a file
Relying on the 3rd party API to be able to seed our database to run tests is a horrible idea. However, we can fix that by caching the response JSON in a file.
How will this data be tunneled into the test database?
In the spirit of limiting the change footprint, we could update the BinanceMock module to serve the cached data dependent on the flag -
let’s add that flag first:
# /config/config.exs
# add below lines under the `import Config` line
config :binance_mock,
use_cached_exchange_info: false# /config/integration.exs
# add below lines under the `import Config` line
config :binance_mock,
use_cached_exchange_info: trueWe can see how convenient it is to have a configuration file per environment - we enabled cached exchange info data only for the test environment.
Inside the BinanceMock module, we can now update the get_exchange_info/0 function to use this configuration value
to serve either cached or live exchange info response:
# /apps/binance_mock/lib/binance_mock.ex
def get_exchange_info do
case Application.get_env(:binance_mock, :use_cached_exchange_info) do
true -> get_cached_exchange_info()
_ -> Binance.get_exchange_info()
end
end
# add this at the bottom of the module
defp get_cached_exchange_info do
{:ok, data} =
File.cwd!()
|> Path.split()
|> Enum.drop(-1)
|> Kernel.++([
"binance_mock",
"test",
"assets",
"exchange_info.json"
])
|> Path.join()
|> File.read()
{:ok, Jason.decode!(data) |> Binance.ExchangeInfo.new()}
endAs the binance_mock app wasn’t using the jason package before, we need to add it to dependencies:
The above change will take care of flipping between serving the live/cached exchange info data, but we still need to manually save the current response to the file (to be used as a cached version later).
Let’s open the terminal and create a new assets directory and fetch the exchange info data and serialize it to JSON:
$ mkdir apps/binance_mock/test/assets
$ iex -S mix
....
iex(1)> {:ok, info} = Binance.get_exchange_info()
...
iex(2)> data = info |> Map.from_struct() |> Jason.encode!(pretty: true)
...
iex(3)> File.write("apps/binance_mock/test/assets/exchange_info.json", data)
:okSo we have the BinanceMock updated to serve cached/live responses based on the configuration and cached exchange info response.
The last step is to ensure that seeding uses the BinanceMock module instead of using Binance directly to leverage the above implementation.
15.7 Update seeding scripts to use the BinanceMock
The seed settings script for the Naive application(apps/naive/priv/seed_settings.exs) already uses the BinanceMock.
Inside the Streamer application (apps/streamer/priv/seed_settings.exs) we can see that the Binance module is getting used.
So we can update the fetching part of the script to the following to fix it:
# /apps/streamer/priv/seed_settings.exs
...
binance_client = Application.compile_env(:streamer, :binance_client) # <= new
Logger.info("Fetching exchange info from Binance to create streaming settings")
{:ok, %{symbols: symbols}} = binance_client.get_exchange_info() # <= updatedWe need to update the config to point to the BinanceMock for the streamer application in the same way as we do for the naive application:
# /config/config.exs
...
config :streamer,
binance_client: BinanceMock, # <= added
ecto_repos: [Streamer.Repo]
...as well as swap the binance to the BinanceMock inside the list of dependencies of the Streamer app:
At this moment, we should be ready to run our test using the test database together with cached Binance response:
$ MIX_ENV=integration mix test.integration
** (Mix) Could not sort dependencies. There are cycles in the dependency graphAnd this is the moment when we will pay for cutting corners in the past. Let me explain.
When we started this project, as we implemented communication using the PubSub topics,
we put both the PubSub process(in the supervision tree) and the TradeEvent struct inside the streamer application.
The knock-on effect of this decision is that any other app in the umbrella that would like to use either PubSub or TradeEvent struct
needs to depend on the streamer application:
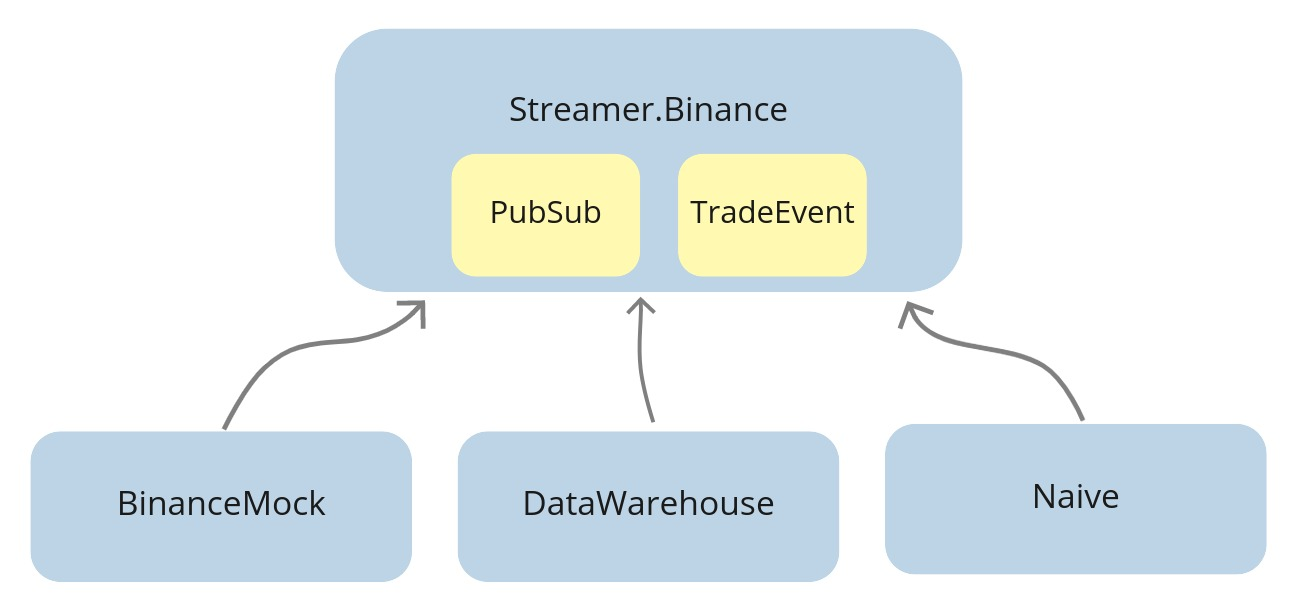
As we added the binance_mock application as a dependency of the streamer application, we created a dependency cycle.
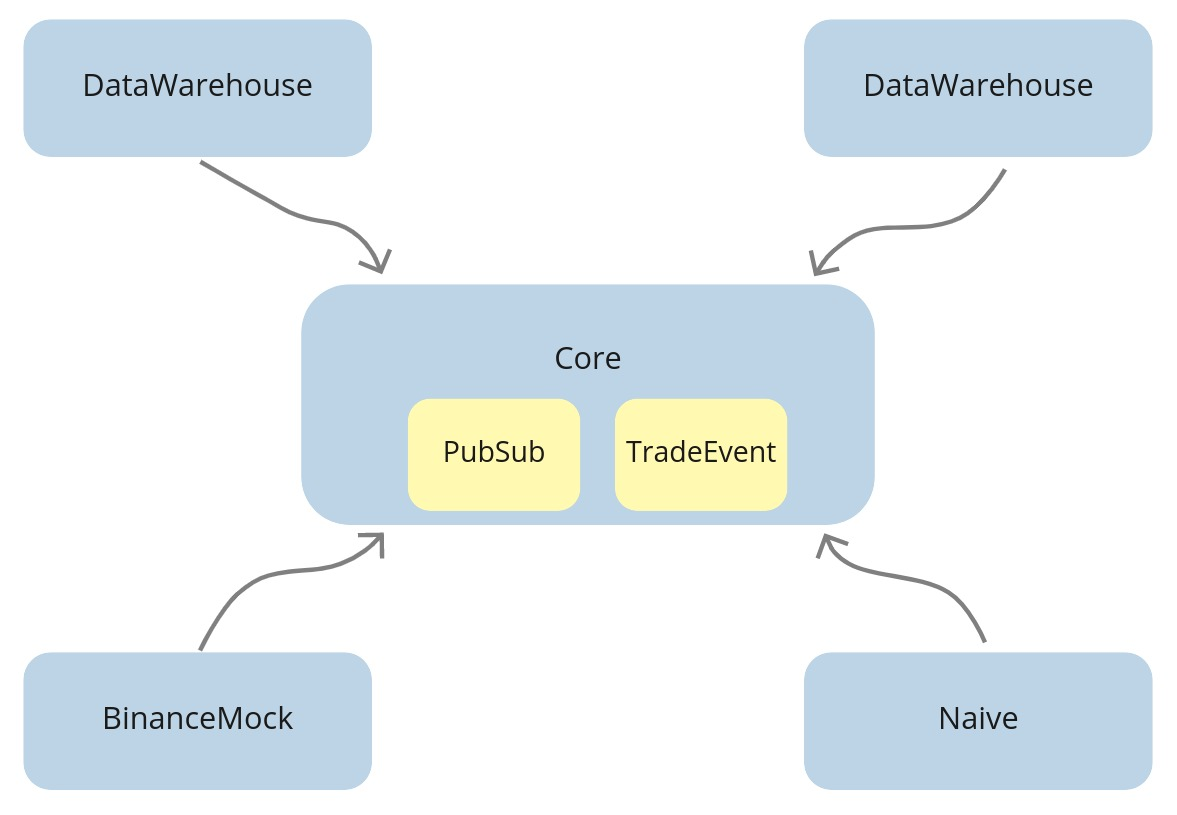
This is quite typical in daily work as a software engineer. One of the common problems(besides naming things) is deciding where things belong. For example, do PubSub and TradeEvent belong in the Streamer app? Or maybe we should put it in the BinanceMock?
I believe they belong in neither - both streamer and binance_mock are consumers of PubSub and TradeEvent, not owners.
What we should do instead is to create a new supervised application where we can attach the PubSub to the supervision tree and hold the system-wide structs(like TradeEvent) so every app can depend on it instead of each other:
15.8 Introduce the Core application
Let’s start by creating a new application:
We can now create a new directory called struct inside the apps/core/lib/core directory and move the TradeEvent struct
from the streamer app to it(in the same terminal or from the apps directory):
Now we need to update the module to Core.Struct.TradeEvent:
As we moved the TradeEvent struct over to the Core application, we need to:
- update all places that reference the
Streamer.Binance.TradeEventtoCore.Struct.TradeEvent - add the
coreto the dependencies lists of all apps in the umbrella - remove the
streamerfrom the dependencies lists of all apps in the umbrella
The final step will be to move the PubSub process from the supervision tree of the Streamer application to the supervision of the Core application.
# /apps/streamer/lib/streamer/application.ex
def start(_type, _args) do
children = [
...
{
Phoenix.PubSub,
name: Streamer.PubSub
}, # ^ remove it from here
...
]# /apps/core/lib/core/application.ex
def start(_type, _args) do
children = [
{
Phoenix.PubSub,
name: Core.PubSub
} # ^ add it here
]As we changed the module name of the PubSub process(from Streamer.PubSub to Core.PubSub),
we need to update all the places where it’s referenced as well as add the phoenix_pubsub package to dependencies of the core application:
We can now run our test that will use the test database as well as cached exchange info:
We should see a lot of setup log followed by a confirmation:
This wraps up our implementation of the end-to-end test. In the next chapter, we will see how we would implement a unit test for our trading strategy.
The additional benefit of all the time that we put in the implementation of this test is that we won’t need to remember how to set up local environment anymore as it’s as simple as:
Yay! :)
We now have automated end-to-end testing. Here’s what we achieved:
- Created a test that broadcasts trade events and verifies orders appear in the database
- Set up environment-based configuration with separate test databases
- Built convenience aliases (
mix setup,mix test.integration) to make testing painless - Fixed a dependency cycle by extracting PubSub and TradeEvent into a new
coreapplication
The key insight is that good architecture pays dividends during testing.
Our pub/sub design meant we could inject test events without modifying production code.
And extracting shared concerns into core not only fixed our cycle - it made the system’s structure cleaner.
It’s worth noting the downsides of end-to-end tests:
- lack of visibility over what’s broken - most of the time, we will see the result of error but not the error itself
- requirement of synchronous execution - they rely on the database(s), so they can’t be run in parallel
- randomness/flakiness - as there’s no feedback loop, we wait for a hardcoded amount of time, that we assume it’s enough to finish initialization/execution - this can randomly fail
It’s possible to implement a feedback loop and run our tests inside “sandbox” (transaction), but it’s not worth it as we can invest that time into developing reliable unit tests.
So, What’s Next?
Speaking of unit tests - end-to-end tests are valuable but expensive. They’re slow, brittle, and when they fail, you’re often left guessing where the problem is.
In the next chapter, we’ll implement proper unit tests using the mox library.
We’ll mock dependencies like PubSub and Binance, test our Naive.Trader in isolation, and get tests that run in milliseconds instead of seconds.
The feedback loop will be tight enough that we can actually use TDD.
[Note] Please remember to run mix format to keep things nice and tidy.
The source code for this chapter can be found in the book’s source code repository (branch: chapter_15).